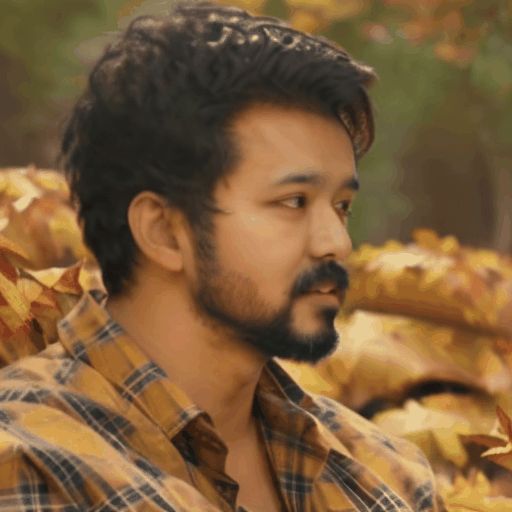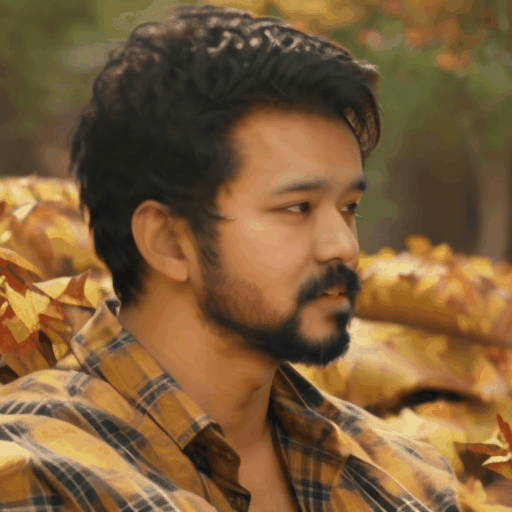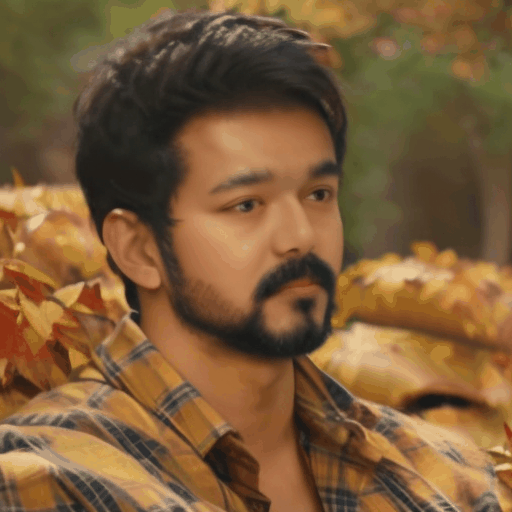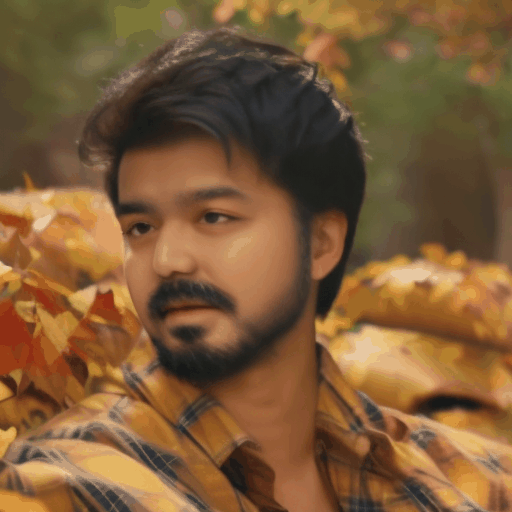🎬 Personalized Facial Animation 🎬

|

|

|
| A close-up of a guy with a relaxed and easygoing expression | A man, wearing a hat, against a beach background | A man with a confident smile, making eye contact with the camera |

|

|

|
| A portrait of a woman in a natural setting, wearing a headband | A close-up shot of a girl with glasses and earrings | A girl adorned with a colorful tattoo on the cheek |

|

|

|
| A man with a goatee and a leather cowboy hat | A man with a piercing gaze against a backdrop of mountain peaks | A man with a surprised and delighted expression, showcasing a moment of unexpected joy |

|

|
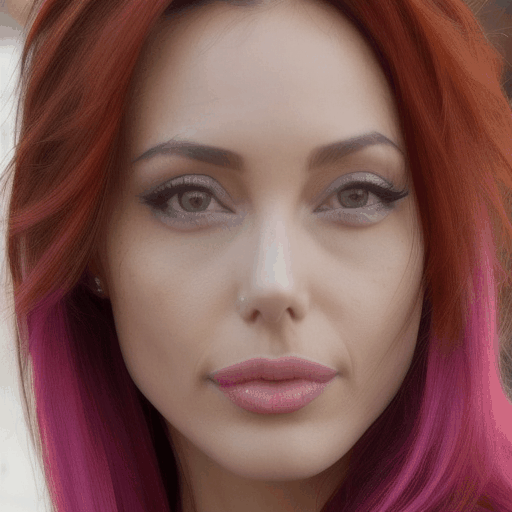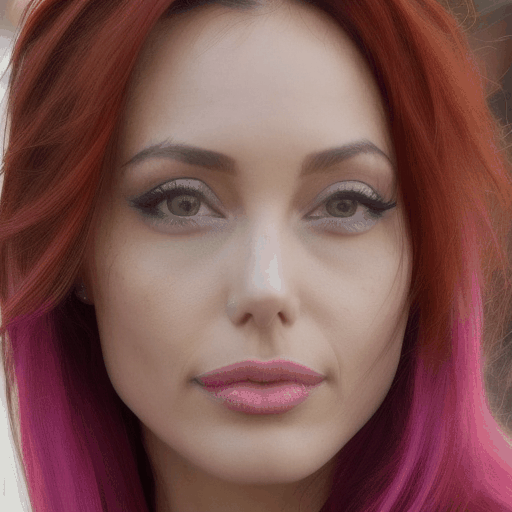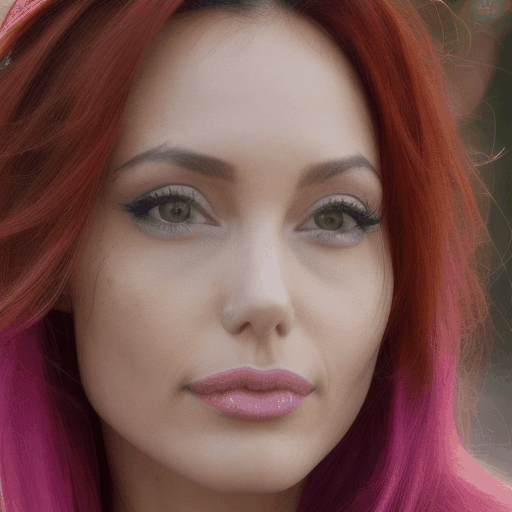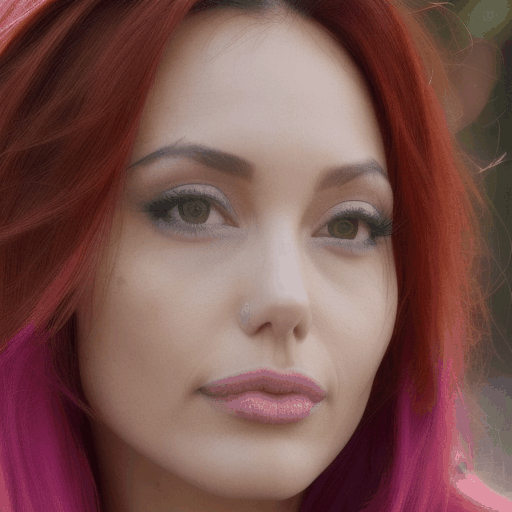
|
| A beautiful woman starts to talk, bright, beautiful face, realistic, solo | A close-up shot of a woman with elegant pearl earrings and a vintage hairstyle | A close-up shot of a woman with vibrant, multicolored hair |
Our main results. We select four representative LoRA character and perform personalized facial animation. Each line represents a different LoRA character (from top to bottom: Liam Neeson, Asian Girl, Suriya Sivakumar, Angelina Joile). For each LoRA character, we have employed three prompts to generate facial animations. The prompt corresponding to each video clip is annotated below it. Our FACC works effectively and generate frame-consistent results on diverse characters and prompts. Moreover, two advantages of FACC can be reflected in the above results: (1) face identity fidelity (2) editing capabilities by text prompts. Due to our key-frame strategy, we can better maintain fidelity to characters and text prompt, without being compromised by the motion module.